{kind=link}
Abstract
We collect the first gourmet dataset, namely LiveFood, to explore the domain incremental video highlights detection. Besides, we also propose Global Prototype Encoding (GPE) to tackle this problem, which yields competitive performance compared to the classic techniques.
LiveFood consists of over 5100 gourmet videos, including four domains which are ingredients, cooking, presentation, and eating. All these videos are finely annotated by the qualified workers. Meanwhile, we introduce a strict double-check mechanism to further guarantee the quality of annotations.
GPE aims to tackle forgetting while still improving by learning new concepts. As analyzed in our manuscript, conventional incremental learning methods have shortcomings, such as overfitting on replayed data, limited flexibility, and unbearable growing architectures. Distinguished from them, GPE employs prototypes together with distance measurement to solve the classification problem. Prototypes are compact and concentrated features learned on the training data, mitigating the effects of overfitting on the stored sub-set. In addition, by using global and dynamic prototypes, we endow the model with appealing capability for further refinement when fed with new data or accommodation to new domain concepts.
Our Framework
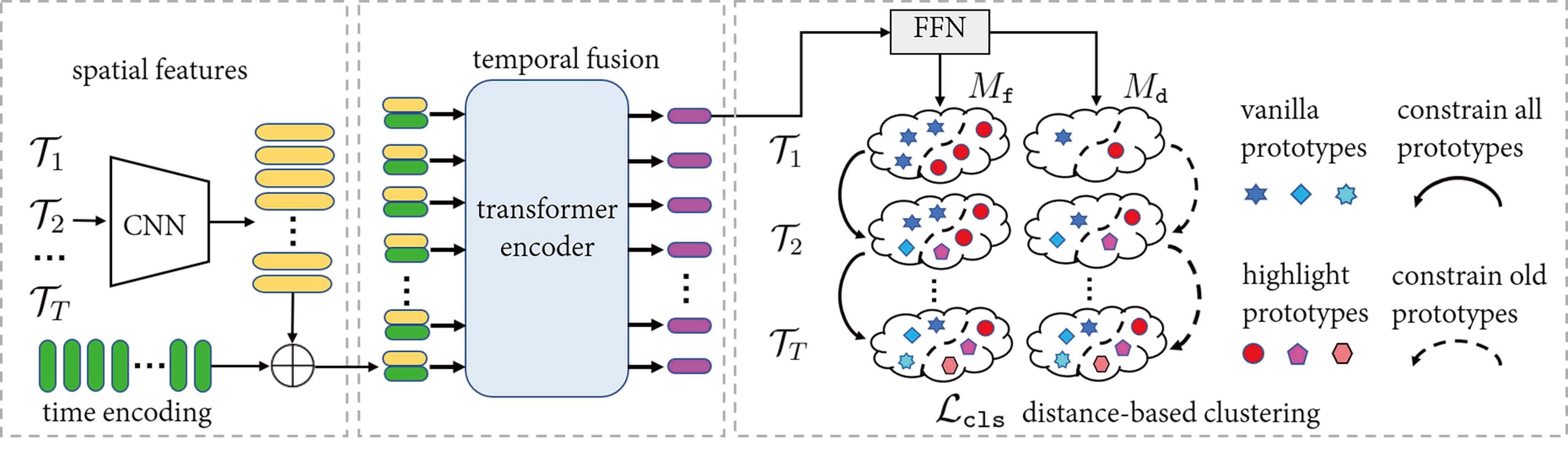
The proposed GPE framework. The input is a training stream with T tasks. In the right-most part, Mf and Md represents the fixed and dynamic modes of GPE. Mf defines the number of prototypes in advance and refines them across different stages. A restriction on the magnitude of change amplitude is imposed during learning. Md dynamically adds new prototypes into the learning process when dealing with new domains. The change restriction is only applied on inherited prototypes. This mode is more suitable when learning on a large amount of domains. Each prototype in above figure is equivalent to a row of V or H.
The LiveFood dataset
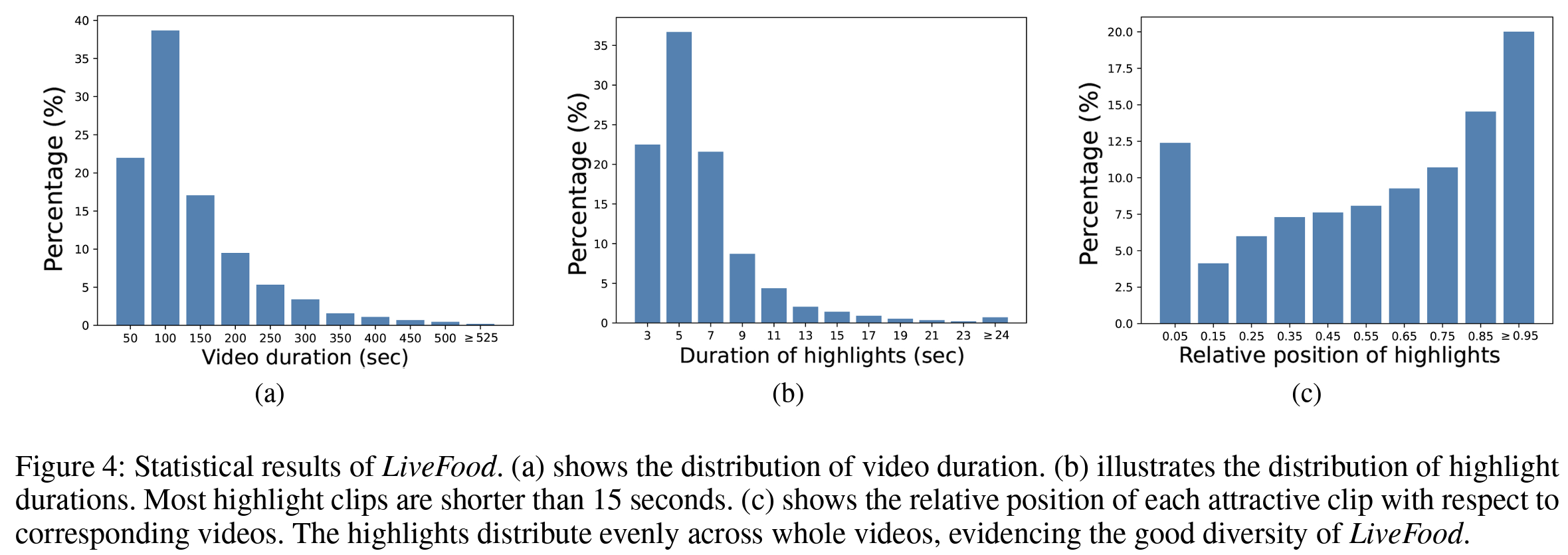
We define four highlight domains that are generally presented in collected videos, namely ingredients, cooking, presentation, and eating. For each domain, a video clip is accepted as a satisfactory highlight if it meets the criteria as stated in our manuscript. The annotators are required to glance over the whole video first to locate the coarse position of attractive clips. Afterward, the video is annotated at frame level from the candidate position to verify the exact start and end timestamps of highlights.